TL;DR:
- Federated data access enables real-time querying across multiple distributed data sources without requiring data movement or duplication. It uses a virtual query engine to translate, dispatch, and aggregate source-specific subqueries, enforcing governance policies and data security at the data layer. Unlike federated learning, which trains models locally, federated data access focuses on retrieving live data efficiently while maintaining strict governance and performance controls.
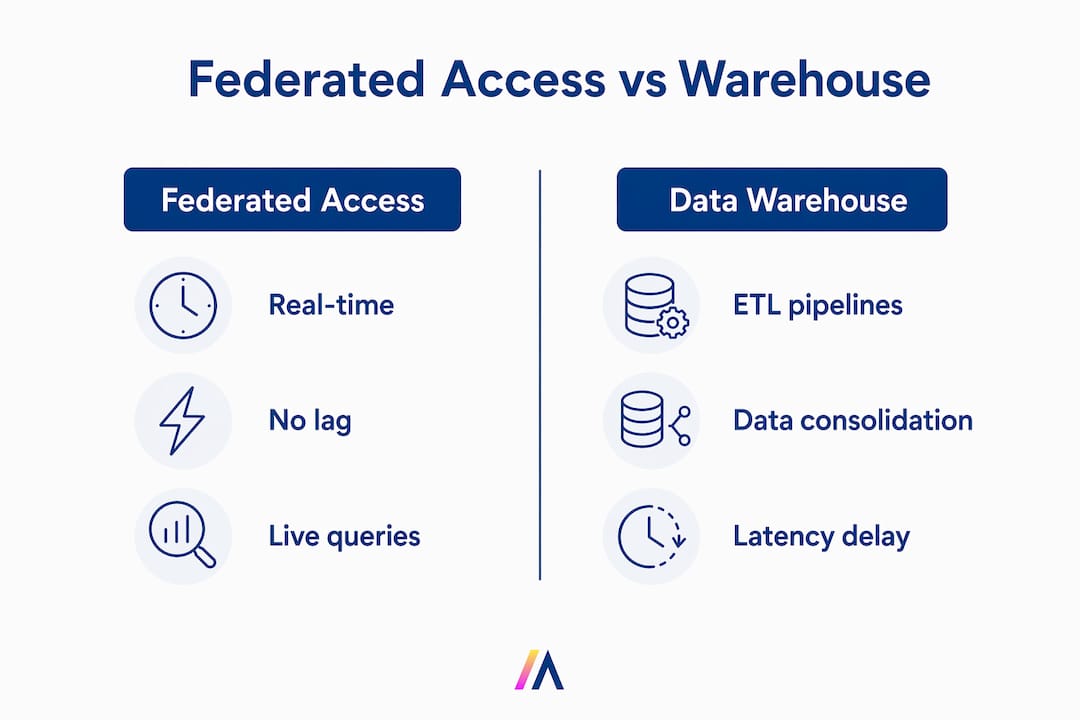
Federated data access for AI is defined as the ability to query and analyze data across multiple distributed sources without physically moving or copying that data into a central repository. Instead of running ETL pipelines to consolidate data from Salesforce, Snowflake, PostgreSQL, and SharePoint into a single warehouse, a federation layer executes queries across all of them simultaneously and returns unified results in real time. This architecture preserves data locality, reduces duplication risk, and keeps AI models working with the freshest possible data. For data professionals and organizational leaders, understanding federated data access is the prerequisite for building AI workflows that are both fast and governable.
Federated data access for AI uses a federation layer or virtual query engine to access multiple data sources without moving data. The engine sits between your AI application and your data sources, translating a single query into source-specific subqueries, dispatching them in parallel, and merging the results before returning them to the requesting model or application. No data warehouse required. No nightly batch jobs. No stale snapshots.
Here is how a typical federated query execution flows:
Pro Tip: When evaluating federated query engines, test predicate pushdown behavior explicitly. Some engines claim federation support but pull full table scans from remote sources, which destroys performance at scale.
Platforms like Databricks implement this by translating and pushing SQL queries to external databases through Unity Catalog, enabling governance and lineage tracking without requiring data ingestion. Oracle’s data federation architecture follows the same pattern: query-time unification rather than centralization, so AI applications always access fresh data without heavy ETL pipelines.

These two terms share a word and cause significant confusion in enterprise AI planning. They solve different problems entirely.
Federated learning trains AI models locally on dispersed data without centralizing training data. Each node trains a local model on its own data, then shares only model weights or gradients with a central coordinator. The coordinator aggregates these updates into a global model. The raw data never leaves its origin. Google’s Gboard keyboard uses federated machine learning to improve next-word prediction without sending users’ keystrokes to a central server.
Federated data access, by contrast, does not train models at all. It queries existing data across distributed sources to retrieve information that an AI application or analyst needs right now. The distinction matters for strategy:
The AI data privacy goals are related but the technical implementations are entirely separate. Choosing the wrong approach wastes months of engineering effort.
Federated data access expands what AI systems can see. That expansion demands proportionally stronger controls. The core framework is data access governance (DAG), which enforces least-privilege access, monitors usage, and audits federated data environments. DAG policies define who can access which data, under what conditions, and with what level of visibility into the results.
The critical insight here is that application-layer controls alone are insufficient for federated AI access governance. Enforcing least-privilege and auditability at the data layer is non-negotiable. If your AI agent can bypass row-level security by querying a federated source directly, your governance posture has a gap regardless of what your application firewall says.
Effective governance in federated AI environments requires several technical controls:
Monitoring AI tool access is critical to closing visibility gaps in federated data environments. Shadow AI, where employees use unauthorized AI tools that query federated sources outside governance controls, represents a growing risk in 2026. DAG frameworks that extend to AI tool governance are the answer.
Pro Tip: Map every data source in your federation layer to a data classification tier before deploying AI agents. Sources containing PII, financial records, or regulated data should require explicit policy approval before an AI agent can query them.
Federated data access excels in specific scenarios and struggles in others. Knowing the difference determines whether your AI deployment succeeds or stalls.
| Scenario | Federated access | ETL/Data warehouse |
|---|---|---|
| Real-time AI queries on live data | Strong. No lag from batch ingestion. | Weak. Data is as fresh as the last pipeline run. |
| Regulatory compliance (data residency) | Strong. Data never leaves its origin jurisdiction. | Weak. Consolidation may violate data residency rules. |
| High-frequency aggregation queries | Weak. Network and source performance limits degrade large aggregations. | Strong. Pre-aggregated data returns fast. |
| Ad hoc or surgical queries | Strong. Targeted queries across sources return quickly. | Moderate. Requires schema alignment in advance. |
| AI agent needing cross-source context | Strong. Agent queries Salesforce, Jira, and Slack simultaneously. | Moderate. Requires all sources to be pre-ingested. |
The performance reality is direct: large-scale aggregations across multiple sources degrade performance compared to centralized systems. A federated query joining 50 million rows across three databases will be slower than the same query against a pre-built data warehouse. This is not a flaw. It is a design characteristic that informs when to use federation and when not to.
The recommended approach for most enterprise AI deployments is hybrid. Use federated access for live, targeted queries where data freshness matters. Use materialized views selectively for high-frequency datasets where query latency is unacceptable. Databricks, for example, supports this pattern natively: federation for ad hoc AI agent queries, materialized views for dashboards and batch analytics that run hundreds of times per day.
Concrete AI use cases where federated data access delivers clear value include cross-source data analysis by AI agents querying CRM, ERP, and ticketing systems in a single response, real-time business intelligence where executives need live operational data without waiting for warehouse refresh cycles, and regulatory reporting where financial or healthcare data must remain in its origin system while still being queryable for compliance audits.
The network dependency is real. If a source system is slow or unavailable, the federated query either waits or fails partially. Circuit breakers and query timeout policies at the federation layer are not optional. They are the difference between a resilient AI workflow and one that fails silently when a backend database is under load.
Federated data access for AI enables real-time, governed querying across distributed data sources without data movement, making it the right architecture for AI workflows that require freshness, compliance, and cross-system context simultaneously.
| Point | Details |
|---|---|
| Core definition | Federation queries multiple sources in place using a virtual engine, eliminating ETL and preserving data locality. |
| Not federated learning | Federated learning trains models without sharing data; federated access queries live data across systems. These are separate strategies. |
| Governance is non-negotiable | Least-privilege access, row-level security, and query guardrails must be enforced at the data layer, not just the application layer. |
| Performance is use-case dependent | Federation excels at ad hoc and surgical queries; use materialized views for high-frequency aggregation workloads. |
| Hybrid architecture wins | Combining federated access with selective materialization delivers both freshness and performance for enterprise AI deployments. |
I have watched organizations deploy federated query engines with genuine enthusiasm, only to hit a wall six months later because they treated federation as a replacement for all data architecture rather than a complement to it. The most common mistake is scope creep: teams start federating two or three sources, see that it works, and then federate everything including high-frequency reporting datasets that should have been materialized from day one. The result is a federation layer under constant load, slow AI responses, and frustrated users who blame the AI rather than the architecture.
The second mistake is underinvesting in governance before the first AI agent goes live. The AI data quality and integration challenges that surface in federated environments are not just technical. They are organizational. Who owns the access policy for a federated source? Who approves an AI agent’s request to query a new database? Without clear answers, governance becomes reactive rather than proactive.
My honest recommendation for 2026: treat your federation layer as a governed API surface, not a transparent data pass-through. Every source that enters the federation should have a data owner, a classification tier, and an approved list of AI agents or roles that can query it. This sounds bureaucratic until the first time an AI agent inadvertently surfaces confidential compensation data in a response to a manager who had no business seeing it.
The technology is mature enough. Databricks Unity Catalog, Oracle Data Federation, and purpose-built federation proxies like QueryFlux all deliver solid query execution. The differentiator in 2026 is governance discipline, not query engine selection.
— Matthieu
Hymalaia’s enterprise AI agent platform is built for exactly the architecture described in this article. Hymalaia connects with over 50 enterprise data sources including Salesforce, Slack, Google Workspace, and SharePoint, executing cross-source AI queries without requiring data consolidation. Its governance layer enforces role-based access controls, dynamic masking, and full audit logging across every federated query an AI agent executes. For organizations that need real-time AI insights with GDPR-compliant data handling, Hymalaia delivers the federation, governance, and agent intelligence in a single platform. Explore the full platform capabilities or book a demo at Hymalaia.com to see federated AI in action.
Federated data access for AI is the ability to query multiple distributed data sources simultaneously through a virtual query engine without physically moving or copying data. The federation layer pushes subqueries to each source, aggregates results, and returns a unified response to the AI application.
A data warehouse consolidates data from multiple sources into a single store through ETL pipelines, which introduces latency and duplication. Federated data access queries sources in place at query time, delivering fresher data without ingestion overhead, though with higher per-query latency for large aggregations.
The primary risks are unauthorized AI tool access to sensitive sources and insufficient enforcement of least-privilege policies at the data layer. Effective mitigation requires row-level security, dynamic masking, query guardrails, and integration with enterprise identity and access management systems.
Use federated data access when your AI application needs to read live data across multiple systems without centralizing it. Use federated machine learning when you need to train AI models across data that cannot leave its origin due to privacy or regulatory constraints. The two approaches address different problems and can be deployed together.
Yes, federated data access is well-suited for real-time, targeted queries where data freshness matters. For high-frequency aggregation workloads, combine federation with materialized views to balance live access with acceptable query performance.
