TL;DR:
- Data masking is a vital but insufficient security layer in AI environments, requiring combination with encryption and access controls to prevent data breaches. GDPR compliance depends on ensuring masking methods are truly irreversible and properly documented, as pseudonymized data can still be personal data. Implementing layered controls like row-level security, audit logs, and threat detection is essential to protect sensitive AI data effectively.
Enterprises feeding sensitive data into AI systems face a problem that doesn’t get enough candid attention: data masking is widely deployed, yet frequently misunderstood as a complete security solution. The role of data masking in AI environments goes well beyond simply hiding a Social Security number in a dashboard. It shapes how AI teams access training data, how compliance officers satisfy regulators, and how IT architects defend against exposure at every layer of the pipeline. Get the implementation wrong, and you face both regulatory liability and real breach risk. This article cuts through the noise.
| Point | Details |
|---|---|
| Masking is not a security boundary | Dynamic masking is a presentation layer control and must be combined with encryption and access controls to be effective. |
| GDPR still applies to masked data | Pseudonymized data remains personal data if re-identification is possible by any party within the same domain. |
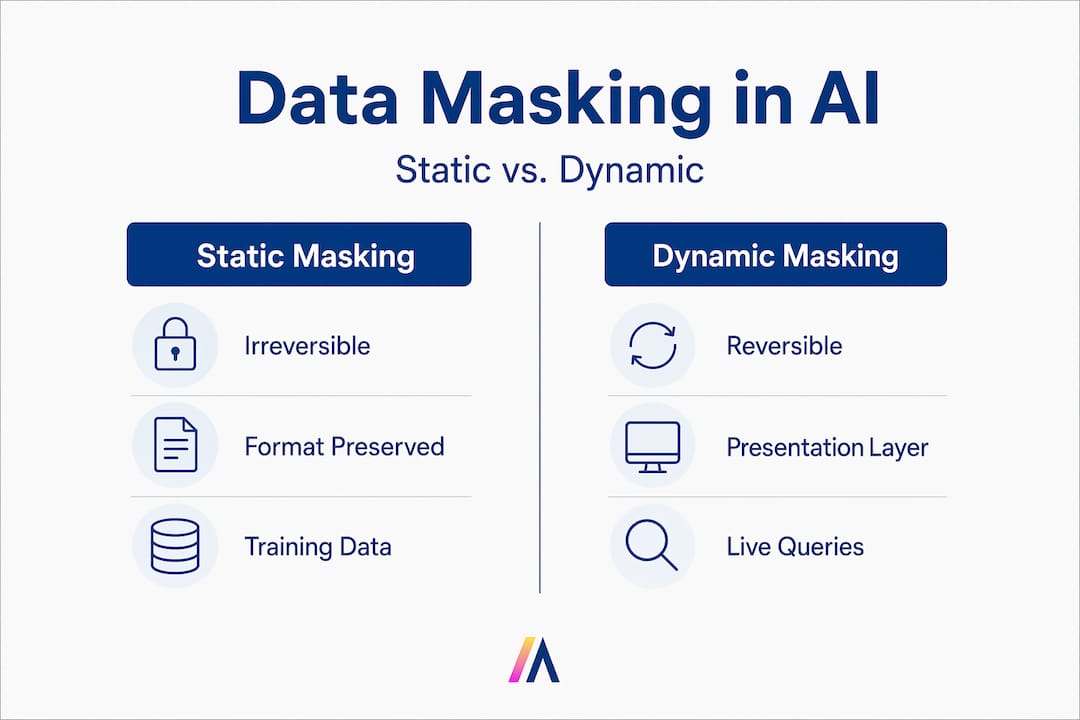
| Static vs. dynamic masking serve different needs | Static masking suits AI training datasets; dynamic masking controls live query access in production systems. |
| Bypass risks are real and documented | Inference attacks and unmasked backups can expose sensitive values even when masking policies are active. |
| Layered controls are non-negotiable | Combining masking with row-level security, audit logs, and zero trust principles produces defensible AI data protection. |
Data masking replaces sensitive values with realistic but fictitious substitutes, preserving the format and structure that AI models and analytics tools expect. A customer email becomes "x.user@domain.com`. A credit card number retains its 16-digit format but carries no real value. This format fidelity matters enormously in AI contexts, because masked data lets developers work with realistic datasets during model training and testing without exposing raw personal information.
Two primary masking types dominate enterprise AI pipelines:
Neither approach encrypts data at rest. Neither removes sensitive values from the database. This distinction separates masking from tokenization (which replaces values with opaque tokens stored in a separate vault) and from anonymization (which irreversibly removes the link to the individual). Understanding where masking sits in that spectrum directly determines your compliance posture.
| Technique | Reversible | Data format preserved | Underlying data protected | GDPR personal data |
|---|---|---|---|---|
| Static masking | No | Yes | Yes (separate copy) | Depends on re-identification risk |
| Dynamic masking | Yes (source intact) | Yes | No | Yes |
| Tokenization | Yes (via vault) | Configurable | Yes | Yes |
| Anonymization | No | Configurable | Yes | No (if truly irreversible) |

The most consequential misconception in enterprise AI programs is the assumption that applying a mask equals achieving anonymization under GDPR. It does not. The EDPB 2025 guidelines make clear that masked or pseudonymized data remains personal data if any party within the pseudonymization domain can reverse the transformation. Your AI platform, your DBA team, and your vendor all potentially constitute that domain.
The EDPB reframes the compliance question from “did we mask?” to “is this masking truly irreversible and unlinkable?” That is a much harder bar to clear, and most enterprise DDM deployments do not clear it.
“Regulators are no longer satisfied with checkbox masking. They want documented evidence that the masking method is appropriate, consistently applied, and tested against re-identification risk.” — EDPB 2025 guidance interpretation
When masked data remains subject to GDPR, your obligations include maintaining a lawful basis for processing, responding to data subject access requests against the masked records, and honoring deletion rights. A masked training dataset that retains linkability to a real individual is still in scope.
Pro Tip: Document your masking rationale in your Records of Processing Activities (RoPA). Regulators require documented evidence of the masking method and compliance justification. A masking policy that exists only in code and not in your compliance documentation will not survive an audit.
The EDPB documentation requirement also extends to the classification of your masking approach. For each AI dataset or data pipeline, you should specify whether the masking constitutes pseudonymization (reversible, GDPR applies) or anonymization (irreversible, GDPR does not apply). That classification should be reviewed whenever the data is used in a new AI context or shared with a new system.
The mechanics of DDM in AI environments are more fragile than most teams expect. Platforms like Databricks implement column masks at query fetch time, applying role-aware functions that control what a given user identity sees when a query returns. This approach is precise. It also introduces complexity that requires careful governance.
Here are the four most commonly underestimated technical risks:
The critical takeaway is that DDM is a presentation layer feature, not a security boundary. Treating it as one is how sensitive data gets exposed in production.
Understanding how data masking supports AI security means accepting that masking alone covers only one attack vector. The scenarios where masking is insufficient are common in enterprise AI programs:
Each of these gaps requires a different control. The layered security strategy that actually protects AI data combines:
Pro Tip: Enforce masking policies at the workspace or fleet level, not per table or per column in isolation. Managing masking field by field across a large AI environment guarantees inconsistency. Centralized policy management via your Identity Provider reduces configuration drift and makes audits faster.
When building privacy-aware AI training datasets, the combination of static masking for the training data plus access controls and audit logging for the pipeline is the minimum viable protection stack. Not masking alone.
I’ve watched enterprise AI programs invest heavily in DDM configuration and then treat the compliance checkbox as done. What I’ve found, working through real implementation cycles and post-audit reviews, is that the most dangerous gap is not technical. It is organizational.
Teams configure masking in one environment and forget backups. They document the policy in the ticket system and skip the RoPA. They rely on platform defaults and never test whether those defaults hold under the actual query patterns their AI analysts use. The inference attack vector is a perfect example. It’s not obscure. It’s in the vendor documentation. But it doesn’t get addressed because the team that implemented masking is not the team thinking about adversarial query patterns.
My take on the EDPB 2025 guidance is that it is genuinely useful for IT and compliance teams willing to engage with it honestly. It forces the question that should have been asked from the start: not “did we apply masking?” but “could anyone in our organization reconstruct this data?” That question leads to the right architecture. Encryption plus masking plus RLS plus audit logs, tested against realistic threat scenarios, not just compliance checklists.
The future trend I’m watching is context-aware masking. Policies that adapt based on the sensitivity of the AI query context, the identity of the requesting agent, and the downstream use of the data. That’s where the field is heading, and enterprises that build centralized policy infrastructure now will be positioned to adopt it without a full rebuild.
— Louis
Hymalaia’s enterprise AI platform is built from the ground up with the governance and data protection controls that AI environments demand. Role-based access controls, GDPR-compliant data handling, and audit trails are not add-ons at Hymalaia. They are core to how the platform operates across cloud, on-premise, and hybrid deployments.
If you are building or scaling enterprise AI and need a platform that integrates masking-aware data governance with real-time AI agents, automated workflows, and over 50 enterprise tool connections, Hymalaia delivers the architecture your compliance team can stand behind.
Explore the full enterprise AI platform or review the advanced platform features that support data privacy and control at scale. Ready to see it in action? Book a demo and see how Hymalaia turns your protected enterprise data into real business intelligence.
Data masking in AI environments protects sensitive fields in datasets used for model training, testing, and analytics, replacing real values with realistic substitutes that preserve data format and usability. It is one layer in a broader data protection strategy, not a standalone security control.
Not automatically. The EDPB 2025 guidelines confirm that pseudonymized or masked data remains personal data if any party within the processing environment can reverse the transformation, meaning GDPR obligations still apply.
Yes. DDM is a presentation layer control and can be bypassed through inference attacks using WHERE clauses or range queries, as well as through direct access to unmasked backups and replicas. Layered controls including encryption and audit logging are required to close these gaps.
Static masking permanently transforms data before it reaches a non-production environment, making it the right choice for AI training datasets. Dynamic masking applies at query time in production systems, controlling what different user identities see without altering the underlying data.
Compliance officers should record the masking method, classification as pseudonymization or anonymization, re-identification risk assessment, and the lawful basis for processing in the organization’s Records of Processing Activities. Regulators expect documented evidence, not just technical configuration logs.
