TL;DR:
- Data sovereignty in AI extends beyond data storage, encompassing control over all AI lifecycle artifacts and operational layers. Legal frameworks like the U.S. CLOUD Act and GDPR impose cross-border obligations that require technical controls, such as customer-managed keys and continuous assessments, for effective compliance. Organizations must map data flows, enforce architecture-level sovereignty measures, and actively manage vendor relationships to mitigate hidden risks and ensure true operational control.
Understanding why data sovereignty matters in AI deployment goes far beyond knowing where your data lives. Most organizations believe that storing data in a local data center or selecting a regional cloud provider is enough to satisfy sovereignty requirements. It is not. True sovereignty spans every phase of the AI lifecycle, from initial data sourcing through model training, inference, and eventual retirement. For business leaders, compliance officers, and IT professionals, the gap between perceived and actual control is where regulatory exposure and operational risk quietly accumulate.
| Point | Details |
|---|---|
| Sovereignty covers the full AI lifecycle | Governance must apply to data sourcing, training, inference, and retirement, not just storage location. |
| Derived AI artifacts are regulated assets | Embeddings, model weights, and vector indexes carry the same compliance obligations as original training data. |
| CLOUD Act exposure transcends borders | U.S. provider possession triggers legal access obligations regardless of where data physically resides. |
| Customer-held encryption keys close critical gaps | When organizations retain exclusive key custody, vendors cannot hand over readable data even under legal compulsion. |
| Contracts alone cannot enforce sovereignty | Technical controls like identity management, audit trails, and key custody must back every contractual commitment. |
The term “data sovereignty” gets used loosely. Ask ten technology leaders to define it and most will describe a data residency policy. Ask them to explain how it applies to a fine-tuned language model or a vector index built from customer support tickets, and the conversation gets uncomfortable quickly.
AI sovereignty must cover data sourcing, training, inference, monitoring, and retirement, and it must regulate model artifacts the same way it regulates training data. This is a materially different challenge than simply choosing a data center location.
The AI lifecycle produces several categories of derived assets, each carrying compliance implications:
Treating sovereignty as a storage-layer decision means every one of these assets remains ungoverned. Encryption, key management, and operational governance must apply across all of them.
Pro Tip: When auditing your AI governance posture, map every artifact your AI system produces, not just the input data. Model weights, embeddings, and inference logs each need their own residency, access, and retention policies.
The legal terrain around AI data sovereignty is more complex than most compliance teams anticipate. Two frameworks in particular create obligations that cannot be satisfied by geography alone.
The EU’s General Data Protection Regulation imposes strict conditions on transferring personal data outside the European Economic Area. Article 44 prohibits such transfers without an adequacy decision, Standard Contractual Clauses, or an applicable exception. Following the Schrems II ruling, organizations must also complete Transfer Impact Assessments to evaluate whether destination country laws undermine the protections SCCs are meant to provide. These TIAs cannot be completed once and filed. TIAs must be treated as living documents, influencing ongoing AI architecture decisions about where and how data and models are processed.
“Where organizations rely on Standard Contractual Clauses for transfers to non-adequate countries, they must assess destination-country laws and implement supplementary technical measures if SCCs alone are insufficient.” — GDPRLedger
Multi-jurisdictional AI deployments compound this further. If your AI vendor uses sub-processors in multiple countries, you inherit compliance obligations across all of them. The accountability sits with you, not the vendor.
Most sovereignty breaches do not originate in primary cloud infrastructure. They happen in the spaces organizations overlook.
Sovereignty failures often occur in vendor chains and unstructured data channels beyond the primary cloud provider. Email threads, file-sharing platforms, and API integrations with third-party analytics tools all create exposure. Your organization is the data controller and remains liable for processors and sub-processors throughout the chain.

AI systems are particularly vulnerable here because they aggregate data from many sources simultaneously. A retrieval-augmented generation system that pulls from SharePoint, Salesforce, and Slack is also inheriting the sovereignty posture of each of those connections.
| Control | What it does | Why contracts alone fall short |
|---|---|---|
| Customer-managed encryption keys (CMK) | Organization holds keys; vendor holds only ciphertext | Vendor cannot decrypt data even under legal demand |
| Confidential computing | Data processed in hardware-enforced secure enclaves | Prevents access at the infrastructure layer, not just storage |
| Identity and access governance | Granular RBAC with audit trails | Limits human and system access to only what is needed |
| Data segmentation | Isolate sensitive workloads at the architecture level | Reduces blast radius if one environment is compromised |
Customer-held encryption keys represent the most practically defensible control available today. When the data owner holds keys never shared with the vendor, the vendor cannot produce readable data in response to a legal demand. This is not a contractual promise. It is a cryptographic guarantee.
Pro Tip: Require auditable evidence of control, not just contractual assertions, from every AI vendor in your supply chain. Vendor sovereignty requires auditable evidence or architectures that eliminate vendor access to plaintext data entirely.
Knowing the risks is necessary. Acting on them requires structured, repeatable processes that span governance, architecture, and procurement.
Before selecting platforms or drafting policies, document the complete data journey across the AI lifecycle. This means identifying every system that contributes training data, every inference endpoint that receives queries, and every location where model artifacts are stored or cached. Many organizations discover sovereignty gaps at this stage that were invisible in their original architecture reviews.
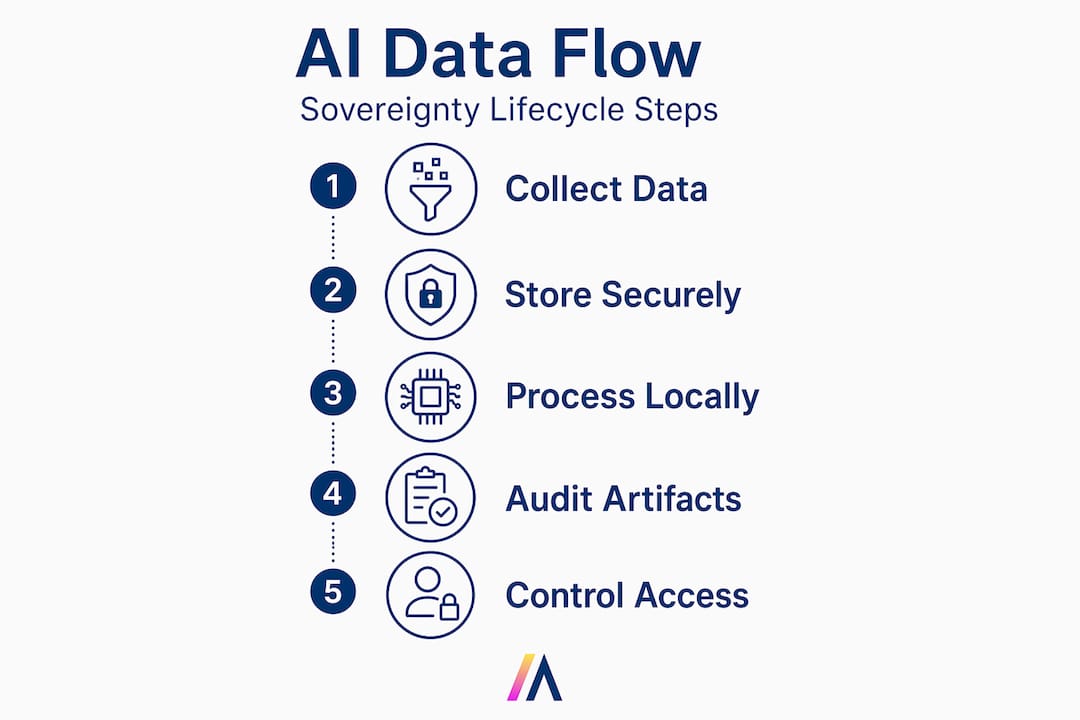
Integrate this mapping into your data governance in AI practice, not as a one-time exercise but as a continuous process that updates when systems, vendors, or workloads change.
Vendor selection decisions have permanent sovereignty implications. Before signing contracts with AI platform providers, require disclosure of all sub-processors, the jurisdictions in which they operate, and the technical controls in place to limit their access to your data. Review responsible AI governance practices to build procurement frameworks that address third-party risk systematically.
Review contracts for audit rights that give you visibility into vendor operations, not just service uptime. Sovereignty without the ability to verify it is a compliance gap dressed in paperwork.
I’ve spent enough time working through enterprise AI deployments to know that the hardest conversations are not about technology. They’re about assumptions. Most organizations assume their primary cloud vendor’s compliance certifications extend to every layer of the AI stack. They do not.
What I’ve consistently seen is that the focus on operational authority matters far more than the focus on geography. Who holds the encryption keys? Who governs identity? Who handles incident response, and from which jurisdiction? When I ask these questions in architecture reviews, the answers are often unclear.
The organizations that get sovereignty right treat it as an engineering problem, not a compliance checkbox. They design systems where the vendor is structurally incapable of accessing their data, rather than contractually restricted from doing so. That is a fundamentally different risk posture, and it requires architectural decisions made early, not policy language added late.
Operational control layers are consistently underestimated. Patching, system updates, and incident handling executed offshore weaken sovereignty even when storage is local. The AI teams I respect most have mapped every operational touch point and assigned it a sovereignty classification. Everything else is assumption.
— Matthieu
Hymalaia is built for exactly the governance challenges this article describes. The platform supports flexible deployment across cloud, on-premise, and hybrid environments, giving your organization direct control over where AI workloads run and where data is stored. Built-in RBAC, AES-256 encryption across all data layers, and support for customer-managed key architectures mean you retain control at the cryptographic level, not just the contractual one.
Hymalaia’s auditability features produce immutable logs across every data access event, inference request, and administrative action, giving compliance officers the evidence trail they need for regulatory review. With connectivity to over 50 enterprise tools, including Salesforce, SharePoint, and Slack, Hymalaia’s governance controls extend across your entire data ecosystem.
Ready to deploy AI with sovereignty built in from day one? Explore Hymalaia’s platform capabilities or book a demo to see how Hymalaia supports your compliance and data governance requirements.
Data sovereignty in AI deployment means maintaining legal and operational control over data and all AI-derived artifacts, including model weights, embeddings, and inference logs, across every phase of the AI lifecycle, not just at the storage layer.
No. The U.S. CLOUD Act compels disclosure based on provider possession, not physical data location. If a U.S.-based vendor operates your AI platform, your data can be reached regardless of where servers sit.
When the data owner holds encryption keys and never shares them with the vendor, the vendor holds only ciphertext. Even under a valid legal demand, the vendor cannot produce readable data, making CMK one of the strongest technical controls available.
Embeddings, vector indexes, model snapshots, inference logs, and monitoring telemetry all qualify as regulated assets and require the same residency, access, and audit controls applied to original training datasets.
TIAs must function as living documents under GDPR, reviewed and updated whenever AI architecture changes, new sub-processors are added, or destination-country legal conditions shift.
