TL;DR:
- A GDPR-compliant AI data pipeline embeds privacy controls, access governance, and data residency at every stage.
- Treating compliance as an architectural priority, with governance-as-code, ensures continuous adherence and reduces regulatory risk.
A GDPR-compliant AI data pipeline is defined as a data processing architecture that embeds privacy controls, access governance, and EU data residency enforcement at every stage of the pipeline, from ingestion to model output. Getting this right matters more than ever. Cumulative GDPR fines have exceeded EUR 7.1 billion as of January 2026. That number reflects not just regulatory aggression but the real cost of treating compliance as an afterthought. This guide walks data engineers and compliance officers through the exact steps for a gdpr compliant ai data pipeline setup, covering prerequisites, architecture decisions, common failure points, and long-term audit readiness.
A GDPR-compliant data architecture is not a configuration toggle. It is a set of structural decisions made before the first byte of personal data enters your pipeline. Two foundational requirements define the starting point: a written Data Processing Agreement (DPA) and a governance framework that travels with your code.

A written DPA under Article 28 GDPR is mandatory for every third-party processor your pipeline touches. That DPA must explicitly guarantee EU data residency to avoid triggering complex cross-border transfer obligations under Chapter V of the regulation. Without it, your pipeline is legally exposed the moment data flows to a cloud provider, a vector database, or an external AI inference service. Review the DPA technical requirements for AI projects to understand exactly what contractual guarantees processors must provide.
Governance-as-code embeds GDPR policies directly into the engineering workflow. Access policies, PII classification rules, and retention schedules are version-controlled and tested in CI/CD pipelines alongside application code. This approach means compliance configurations ship with every deployment rather than living in a separate audit spreadsheet. The practical result is that a policy change to a retention schedule triggers the same peer review and automated testing as a schema migration.
Before building, your team needs three things in place:
Pro Tip: Run an automated PII scan across your existing data stores before designing the pipeline. Tools like Apache Atlas or AWS Macie surface hidden PII in fields that engineers assumed were safe, such as free-text comment columns or log payloads.
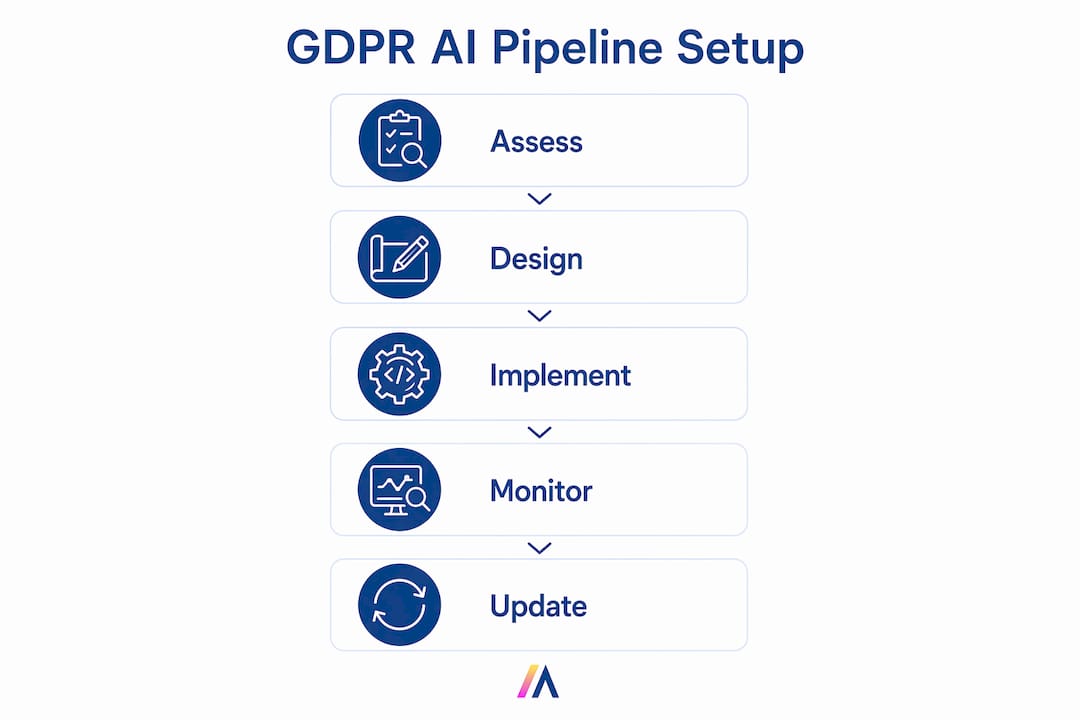
Setting up data pipelines for AI with GDPR compliance requires Privacy by Design baked into each stage. The following sequence covers the full pipeline lifecycle.
Data ingestion with PII detection. At the entry point, run automated PII classifiers against every incoming record. Flag, route, or reject data that does not meet your lawful basis requirements before it enters the pipeline. Schema validation at ingestion prevents unauthorized PII from propagating downstream.
Masking and tokenization layer. Replace personal identifiers with pseudonymous tokens immediately after ingestion. The trust boundary concept is the key GDPR architectural principle here: no raw PII should cross into a third-party AI provider. Tokenization preserves relational integrity so model training still works, while the mapping table stays inside your controlled environment. For a deeper look at this layer, the guide on data masking in AI covers tokenization patterns specific to AI inference pipelines.
Tenant-context aware storage and routing. Tenant-level data isolation with regional routing provides demonstrable GDPR-compliant data residency. Each tenant’s data lives in a dedicated regional store. Routing logic reads tenant context at runtime and directs processing to the correct region. This is auditable. A row-level flag in a shared global table is not.
Model training and output filtering. Training jobs must reference only tokenized datasets. Output filtering checks model responses for PII reconstruction before results reach end users. This step catches cases where a model has memorized personal data from training and attempts to surface it in generation.
Automated DSAR handling. Data Subject Access Requests (DSARs) require a response within one month under Article 17. Automated DSAR orchestration with identity verification, a centralized request repository, and immutable audit logging is the only way to meet that deadline consistently at enterprise scale. Manual scripts fail under volume.
| Approach | Audit Trail Preserved | Relational Integrity | Scalability |
|---|---|---|---|
| Simple row deletion | No | Broken | Low |
| Pseudonymization with token mapping | Yes | Maintained | High |
| Column-level encryption with key deletion | Yes | Maintained | High |
Column-level encryption and audit logging are database-level principles of GDPR compliance for AI systems. Deleting the encryption key for a specific subject effectively erases their data without breaking foreign key relationships or corrupting model training datasets.
Pro Tip: Version your tokenization mapping tables alongside your model versions. When a data erasure request arrives, you need to know exactly which model checkpoints were trained on data that included that subject’s tokens.
The most common failure mode is treating GDPR compliance as a retrofit task. Retroactively adding pseudonymization causes failure in 80% of mid-market AI projects. That statistic reflects a structural problem: once raw PII has propagated through ingestion, storage, and training, there is no clean way to remove it without rebuilding the pipeline from scratch.
Row-level residency flags in shared tables. A flag that says “this record belongs to EU tenant” does not prevent a global query from reading it. True data residency requires tenant-bound regional stores. Regulators ask for proof, not assertions.
Insufficient audit logs. Audit logs must capture who accessed what data, when, and from which system. Append-only, immutable logs are the standard. Mutable logs are inadmissible as compliance evidence because they can be altered after the fact.
Manual DSAR workflows in lakehouse architectures. A data lakehouse with petabyte-scale storage and dozens of processing layers cannot be searched manually for a single subject’s data within a one-month window. Automation is not optional at this scale.
Schema design that collects unnecessary PII. Data minimization under Article 5(1)© requires collecting only what is strictly necessary. Schemas that default to storing full names, IP addresses, and device identifiers “just in case” create compliance debt that compounds with every new model trained on that data.
“GDPR compliance in AI is not a legal problem that engineers implement. It is an engineering problem that legal teams must understand. The architecture decides the outcome, not the policy document.”
Avoiding these pitfalls requires AI data governance best practices that treat privacy as a first-class engineering constraint, not a post-launch checklist item.
Compliance is not a state you reach. It is a property you continuously verify. Governance-as-code makes this tractable by turning compliance checks into automated tests that run on every deployment.
| KPI | Measurement Method | Target |
|---|---|---|
| PII masking coverage | Automated scan at ingestion | 100% of flagged fields |
| DSAR response time | Orchestration workflow timer | Under 30 days |
| Data residency violations | Tenant-region routing audit | Zero cross-region leaks |
| Audit log completeness | Append-only log validator | No gaps in access records |
| Retention policy adherence | Scheduled deletion job reports | 100% of expired records purged |
Article 30 of GDPR requires a Record of Processing Activities (RoPA). Your governance-as-code system should generate this record automatically from pipeline metadata rather than requiring manual documentation. Every processing step, data category, and retention period becomes a machine-readable artifact that auditors can inspect directly.
Staying current with GDPR guidance matters too. The European Data Protection Board regularly publishes updated opinions on AI-specific processing scenarios, including guidance on training data, automated decision-making under Article 22, and data transfers to AI providers. Subscribe to EDPB updates and build a quarterly review cycle into your compliance calendar.
Pro Tip: Treat your compliance test suite the same way you treat your unit test suite. A failing compliance test should block a deployment. If it does not, the governance-as-code framework has no teeth.
For a broader view of how data sovereignty affects AI deployment, including technical strategies for EU residency enforcement, that resource covers the regulatory context that shapes these architectural decisions.
After working through dozens of enterprise AI pipeline reviews, the single clearest pattern I have seen is this: teams that treat GDPR as a legal checkbox always end up rebuilding. Teams that treat it as an architectural constraint ship once and maintain continuously.
The trust boundary concept from Oronts is the most useful mental model I have encountered. Draw a line around your controlled environment. Nothing crosses that line as raw PII. Everything that crosses it is either tokenized, encrypted, or aggregated. That one rule, applied consistently at ingestion, eliminates the majority of compliance risk before a single model trains.
Governance-as-code changed how I think about compliance culture. When access policies and retention rules live in version control, engineers stop treating them as someone else’s problem. A pull request that removes a retention rule gets reviewed the same way a security vulnerability does. That cultural shift is worth more than any compliance tool you can buy.
The hardest conversation I have with engineering teams is about DSAR automation. Most teams underestimate the operational complexity of erasure in a lakehouse. A subject’s data is not in one table. It is in raw ingestion logs, feature stores, training datasets, model checkpoints, and output caches. Automating the discovery and deletion across all of those layers requires upfront architectural investment. The teams that skip it pay for it later, at the worst possible time, when a regulator is waiting for a response.
Build the trust boundary early. Version your governance policies. Automate erasure from day one. These are not aspirational goals. They are the minimum viable architecture for a GDPR-compliant AI pipeline in 2026.
— Matthieu
Building a compliant pipeline is significantly faster when your AI platform handles the governance layer natively. Hymalaia’s enterprise AI platform includes built-in EU data residency options, role-based access controls (RBAC), automated data masking, and immutable audit trail capabilities designed for enterprise compliance requirements.
Hymalaia connects with over 50 enterprise data sources including Salesforce, SharePoint, and Google Workspace, and applies privacy controls at the integration layer so PII never reaches the AI inference layer unprotected. The platform’s advanced governance features support Article 30 RoPA generation, automated DSAR workflows, and tenant-level data isolation out of the box. If you are setting up a compliant AI pipeline and want to reduce the engineering overhead of building these controls from scratch, Hymalaia is built for exactly that workload.
A GDPR-compliant AI data pipeline is a data processing architecture that enforces privacy controls, EU data residency, and subject rights automation at every stage from ingestion to model output. It treats compliance as a structural property rather than a configuration setting.
Organizations must respond to data erasure and access requests within one month under Article 17 GDPR. Automated orchestration with identity verification and audit logging is required to meet this deadline consistently at enterprise scale.
Row-level flags in shared tables do not prevent global queries from accessing EU-resident data. True GDPR-compliant data residency requires tenant-bound regional data stores with routing logic that enforces boundaries at the infrastructure level.
Governance-as-code means access policies, PII classification rules, and retention schedules are version-controlled and tested in CI/CD pipelines. This approach ships compliance configurations with every deployment and makes policy changes subject to the same engineering review as code changes.
Pseudonymization must be applied at the ingestion stage, before data enters storage or training workflows. Retroactively adding pseudonymization after raw PII has propagated through a pipeline fails in the majority of cases and typically requires a full pipeline rebuild.
A GDPR-compliant AI data pipeline requires tenant-level isolation, governance-as-code, and automated DSAR workflows built in from the start, not added after deployment.
| Point | Details |
|---|---|
| Governance-as-code is foundational | Version-control access policies and retention rules so compliance ships with every deployment. |
| Trust boundaries prevent PII leakage | Tokenize or mask all personal data before it crosses into third-party AI providers. |
| Tenant-level isolation beats row flags | Dedicated regional data stores provide auditable proof of EU data residency to regulators. |
| Automate DSAR handling from day one | Manual erasure workflows cannot meet the one-month Article 17 deadline at enterprise scale. |
| Retrofitting pseudonymization fails | Integrate PII masking at ingestion; rebuilding compliance into an existing pipeline costs far more. |
