TL;DR:
- AI data pipelines are automated workflows that ensure continuous, validated data delivery essential for model training, retraining, and deployment. Their design differs from traditional ETL by supporting real-time ingestion, automated quality checks, schema governance, and ongoing observability, which are critical for operational success. Proper pipeline architecture enhances reliability, reduces technical debt, and is fundamental to AI product longevity and enterprise efficiency.
Data pipelines in AI product development are automated workflows that transform raw, multi-source data into timely, validated inputs that AI models require to train, retrain, and serve predictions accurately. Without them, even the most sophisticated model architectures fail. The role of data pipelines in AI product development goes far beyond the traditional ETL (extract, transform, load) pattern. Platforms like dbt Labs and cloud data warehouses like Snowflake have redefined what pipelines must do: enforce schema discipline, support continuous retraining, and deliver feature-ready data at the latency your business demands. Get the pipeline wrong, and your AI product is built on sand.
Traditional data pipelines move data from point A to point B on a schedule. AI data pipelines do something fundamentally different: they keep models alive. The distinction matters because the consequences of failure are asymmetric. A broken ETL job delays a report. A broken AI pipeline silently degrades a recommendation engine, a fraud detector, or a demand forecast, often without any obvious error signal.
The core differences break down across four dimensions:
Pro Tip: Set up automated data quality tests at every pipeline stage before you write a single line of model training code. Catching a null field upstream costs minutes. Catching it after a model deployment costs days.
The operational complexity of AI pipelines also scales differently. Monolithic scripts are costly and hard to maintain; modular approaches are the only architecture that survives production AI workloads. This is why the data engineering role is shifting from writing SQL to designing systems that can govern, test, and orchestrate data at scale.

Understanding the stages of an AI pipeline gives technical leaders a clear map for where to invest, where failures hide, and where automation pays off fastest. The AI development lifecycle runs through six distinct pipeline stages, each with its own failure modes.
| Stage | Traditional pipeline | AI pipeline |
|---|---|---|
| Ingestion | Scheduled batch | Continuous or event-driven |
| Transformation | Static SQL scripts | Versioned, tested dbt models |
| Quality checks | Manual or absent | Automated at every stage |
| Output | Reports and dashboards | Model-ready feature sets |
| Monitoring | Job success or failure | Data drift and prediction drift |
Pro Tip: Treat your feature store as a contract between your data team and your model team. Any feature used in training must be reproducible at serving time, or you will spend weeks debugging phantom accuracy drops.
The integration between pipeline stages and the serving layer is where most enterprise AI products break down. Data integration for AI development is not a one-time setup. It is an ongoing operational discipline that requires clear ownership, SLA definitions, and automated alerting.
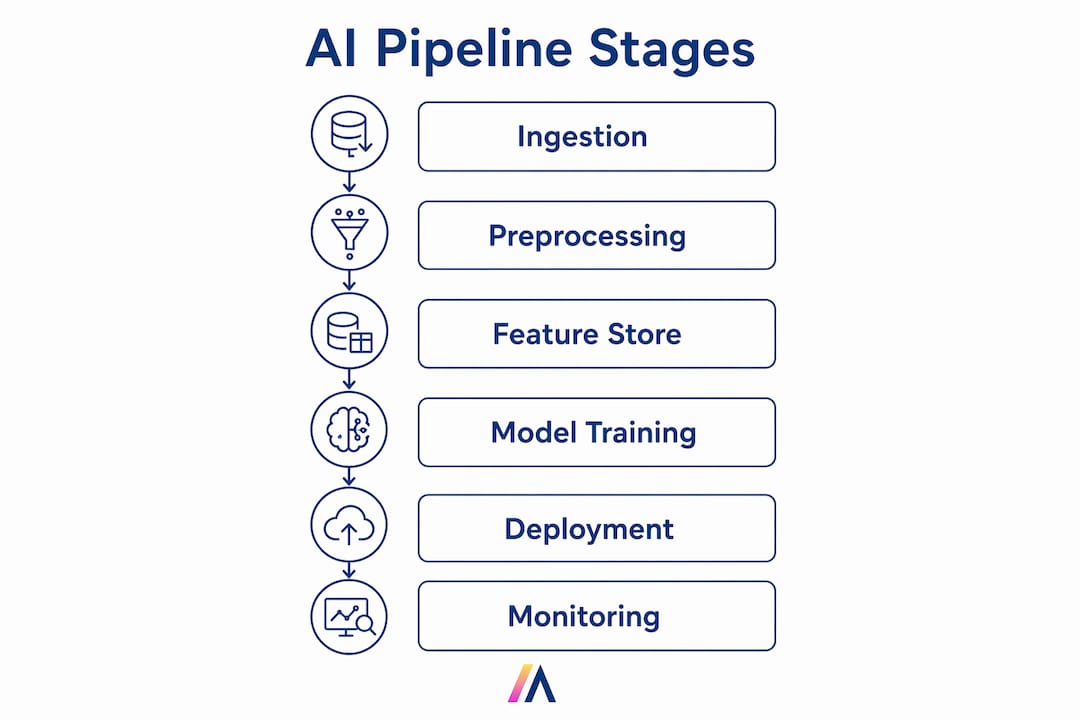
The data pipeline importance in AI extends directly to business outcomes. Over half of generative AI projects fail due to poor architecture and lack of operational rigor. That statistic reflects a pattern Gartner has documented across industries: teams invest in model development while treating pipelines as an afterthought, then abandon projects when deployment costs spiral.
Well-architected AI pipelines reduce this risk through several concrete mechanisms:
“Most AI problems are actually data pipeline problems. The model gets blamed, but the root cause is incomplete, late, or corrupted input data that the pipeline failed to catch.”
The cost of poor pipeline architecture compounds over time. Teams that skip AI governance best practices early in the AI development lifecycle find themselves rebuilding pipelines from scratch after the first major production failure. Building modular, observable pipelines from the start is significantly cheaper than retrofitting them after deployment.
The most effective AI pipeline architectures in 2026 share a common set of design principles. These are not theoretical ideals. They are the practices that separate AI products that survive production from those that get quietly decommissioned after six months.
Pro Tip: Before deploying any AI pipeline to production, run a full failure mode analysis. Ask: what happens if this source goes down, this schema changes, or this job runs three hours late? Every answer should map to an automated alert or fallback behavior.
The workflow for AI product innovation in 2026 increasingly treats pipelines as products in their own right, with their own roadmaps, owners, and reliability targets. Teams that make this shift consistently outperform those that treat pipelines as infrastructure someone else manages.
Data pipelines are the operational foundation of every successful AI product, and architectural choices made early determine whether a model survives production or becomes technical debt.
| Point | Details |
|---|---|
| AI pipelines differ fundamentally | They require continuous ingestion, automated retraining, and schema governance that traditional ETL cannot provide. |
| Six critical stages | From ingestion through monitoring, each stage needs automated quality checks and clear ownership to prevent silent failures. |
| SLAs drive reliability | Defining latency and freshness SLAs before writing code is the single most effective way to prevent model degradation. |
| Automation multiplies productivity | AI-assisted pipeline tooling can increase engineer productivity by up to 50%, freeing teams for higher-value architecture work. |
| Governance starts at the pipeline | Lineage tracking, observability, and modular design are prerequisites for compliant, maintainable AI products at enterprise scale. |
Most technical leaders I work with focus their AI investment decisions on model selection: GPT-4o versus a fine-tuned open-source model, transformer architecture versus gradient boosting. That is the wrong place to focus. The model is the last 20% of the problem. The pipeline is the first 80%, and it is where most projects actually fail.
What I have seen repeatedly is that teams treat pipelines as plumbing. They get built quickly, by whoever has bandwidth, with minimal documentation and no observability. Then six months into production, the model starts underperforming. The team spends weeks tuning hyperparameters before someone finally traces the issue back to a schema change in a source system that silently corrupted three months of training data.
The uncomfortable truth is that AI is your infrastructure, not just your product. That means pipeline reliability engineering deserves the same rigor you apply to your core application infrastructure. On-call rotations, SLA dashboards, incident postmortems: all of it.
I also think the industry underestimates how much the data engineer role is changing. The engineers who will be most valuable in the next three years are not the ones who write the most SQL. They are the ones who understand business domains deeply enough to define the right SLAs, and who can design systems that govern, test, and automate data flows at scale. That shift is already happening, and teams that invest in it now will have a structural advantage.
Start with observability. Before you add another data source or retrain another model, make sure you can see exactly what your pipeline is doing and where it fails. That visibility is worth more than any model improvement.
— Matthieu
Hymalaia’s enterprise AI platform is built for exactly the operational challenges described in this article. The platform connects with over 50 enterprise data sources including Salesforce, Slack, Google Workspace, and SharePoint, enabling real-time data synchronization across your AI product workflows. Its RAG architecture ensures AI agents always query fresh, validated data rather than stale snapshots. With role-based access controls, GDPR compliance, and support for cloud, on-premise, and hybrid deployments, Hymalaia gives technical leaders the governance layer that production AI pipelines demand. Explore the full platform capabilities to see how Hymalaia supports advanced data integration, orchestration, and AI agent automation at enterprise scale.
Data pipelines in AI product development are automated workflows that ingest, clean, transform, and deliver data to model training and serving systems. They determine the quality, freshness, and reliability of every prediction an AI product makes.
AI pipelines require continuous ingestion, automated retraining triggers, feature versioning, and drift monitoring that traditional batch ETL pipelines do not support. The output is model-ready feature sets, not reports.
Gartner reports that over half of generative AI projects fail due to poor architecture and operational gaps, most of which trace back to pipeline design rather than model quality.
Define latency and freshness SLAs before writing code, implement automated quality testing at every stage, use modular versioned transformations, and build observability into the pipeline from the start.
AI-assisted pipeline tooling, including automated SQL generation, test creation, and documentation, increases engineer productivity by up to 50%, allowing teams to iterate faster and focus on higher-value architecture decisions.
