TL;DR:
- Secure AI model deployment involves layered protections across governance, access control, and artifact integrity to ensure safe production environments. It requires continuous risk management, proper inventory, and runtime controls to prevent tampering, data leaks, and attack surfaces throughout the model lifecycle. The actual security perimeter encompasses artifact supply chains, runtime environments, inference APIs, and data pipelines, not just the API gateway.
Secure AI model deployment is defined as the controlled process of moving AI models into production environments with layered protections across governance, access control, encryption, and operational monitoring. The industry term for this discipline is AI model security, and it spans the full lifecycle from artifact packaging to runtime inference. Deployment involves controlled processes across governance, pipeline security, and platform-specific controls rather than simply hosting a model online. Standards like the NIST AI Risk Management Framework (AI RMF) and guidance from Microsoft Azure define the boundaries of what responsible, secure deployment looks like in 2026. For IT professionals and data scientists, getting this right protects model integrity, preserves data confidentiality, and maintains organizational trust.
Secure AI deployment is not a single configuration step. It is a discipline that spans how models are packaged, stored, transferred, served, and monitored. Every phase introduces distinct attack surfaces, and a failure at any one of them can compromise the entire system.

The stakes are high for enterprises. A tampered model weight file can silently degrade output quality or introduce adversarial behavior. An unsecured inference API can leak sensitive customer data embedded in prompts. An untracked AI asset can sit outside your monitoring perimeter entirely. Unknown or untracked AI assets substantially increase attack surface complexity and hinder effective monitoring, making automated inventory critical to any deployment program.
Securing AI also requires a holistic approach spanning development, operations, data handling, and runtime behaviors to address complex and dynamic risks. This means security cannot be bolted on after deployment. It must be designed into the release pipeline from the first training run.
Different deployment patterns including public cloud, private cloud, hybrid, and edge each carry distinct tradeoffs between control, latency, cost, and security posture. Choosing the wrong pattern for your data sensitivity level is one of the most common and costly mistakes in enterprise AI.
| Pattern | Security strengths | Security weaknesses | Best fit |
|---|---|---|---|
| Public cloud (AWS, Azure, GCP) | Managed controls, rapid patching, compliance certifications | Shared infrastructure, data residency risks | Low-sensitivity workloads, rapid prototyping |
| Private cloud | Full infrastructure control, data locality | High operational overhead, slower patching cycles | Regulated industries, sensitive PII |
| Hybrid | Flexibility, sensitive data stays on-premise | Complex trust boundaries, integration attack surface | Mixed-sensitivity workloads |
| Edge inference | Low latency, data never leaves device | Limited monitoring, physical access risks | IoT, real-time inference, air-gapped environments |
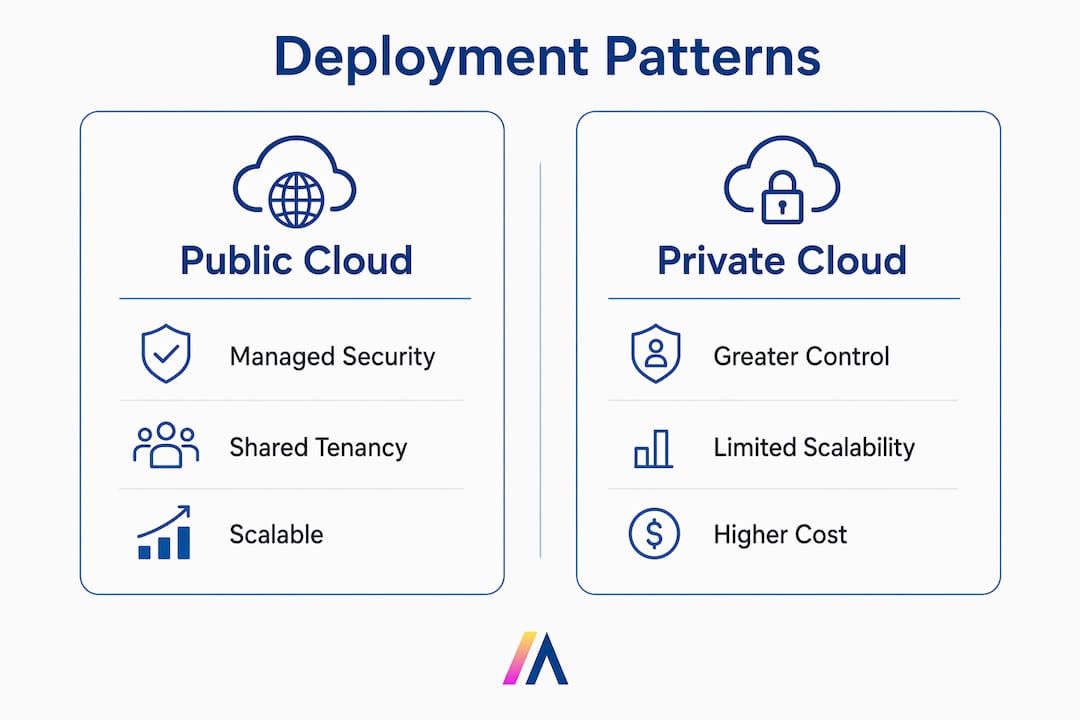
Public cloud deployments on platforms like AWS SageMaker or Azure Machine Learning offer managed security controls and fast compliance certifications, but they introduce shared infrastructure risks and data residency concerns that regulated industries cannot ignore. Private deployments give you full control over the stack, but the operational overhead of patching, key management, and monitoring falls entirely on your team. Edge inference keeps data local and reduces latency, but physical device access and limited telemetry make it the hardest pattern to monitor effectively.
Pro Tip: Before selecting a deployment pattern, classify your data by sensitivity tier. Models processing HIPAA-regulated health data or GDPR-covered personal data belong in private or hybrid environments, not public cloud endpoints.
AI model artifacts include weight files, tokenizer configurations, container images, and metadata manifests. Each of these is a potential target for tampering, substitution, or rollback attacks. Protecting artifacts with signing, versioning, and provenance tracking verifies integrity and origin before any model reaches production.
Secure AI release processes treat model artifacts the same way software engineering treats build artifacts. That means applying cryptographic hashes, signed manifests, and provenance metadata to enable auditability and safe rollback during release pipelines. A model that cannot be verified against a known-good hash should never be loaded into production.
A practical artifact protection program covers these controls:
Pro Tip: Store signing keys in an HSM, never in environment variables or CI/CD secrets managers. A compromised signing key invalidates your entire artifact trust chain.
Secure inference treats prompt handling, APIs, runtime, and storage as a distributed security problem requiring isolation and gateway controls. The moment a model starts serving requests, it becomes a live attack surface exposed to prompt injection, data exfiltration, and API abuse.
Build your inference security in layers:
Pro Tip: Edge inference security failures most commonly occur at API ingress, prompt handling, and retrieval augmentation points. Instrument these three points first before expanding your monitoring coverage.
The NIST AI RMF promotes a full lifecycle, risk-based governance model with four core functions: Govern, Map, Measure, and Manage. These functions give IT and data science teams a structured way to apply continuous risk controls aligned to organizational context and compliance requirements.
| NIST AI RMF function | What it means in deployment | Example control |
|---|---|---|
| Govern | Establish policies, roles, and accountability for AI systems | Define RACI for model owners, security teams, and compliance |
| Map | Identify AI assets, dependencies, and risk contexts | Maintain an AI asset inventory using Azure Resource Graph or similar |
| Measure | Quantify and qualify risks across the AI lifecycle | Run adversarial testing, red-teaming, and bias evaluations pre-launch |
| Manage | Treat identified risks through accept, mitigate, transfer, or avoid | Apply compensating controls, retire high-risk models, or add human review |
The Govern function is where most enterprises underinvest. Without defined ownership and policy, the other three functions produce findings that nobody acts on. Assigning a named model owner for every production AI system, with defined accountability for security incidents, is the single governance change that produces the fastest improvement in deployment security posture.
The Map function connects directly to automated AI asset discovery using tools like Azure Resource Graph and Microsoft Defender for Cloud to maintain a complete, current inventory. An asset you cannot see is an asset you cannot protect. The Measure function then applies both quantitative metrics (API error rates, latency anomalies, failed authentication attempts) and qualitative assessments (red-team exercises, third-party audits) to surface risks before they become incidents.
For responsible enterprise AI programs, integrating NIST AI RMF into existing IT governance structures such as ISO 27001 or SOC 2 audit cycles creates a unified compliance posture rather than a parallel AI-specific program.
Translating frameworks into operations requires a concrete checklist. These controls address the most common gaps in enterprise AI deployments:
For endpoint security in AI agent deployments, add artifact verification before model load, enforce tool-use policies at the agent level, and require human approval for any agent action that touches sensitive data or external systems.
Secure AI model deployment requires layered controls across artifact integrity, runtime isolation, inference gateways, and continuous risk governance to protect enterprise data and model behavior in production.
| Point | Details |
|---|---|
| Define before you deploy | Classify data sensitivity and select the deployment pattern (public, private, hybrid, edge) before writing infrastructure code. |
| Sign and verify artifacts | Apply cryptographic signing and provenance tracking to every model artifact using HSM-managed keys and immutable version registries. |
| Centralize inference controls | Route all model traffic through an authenticated gateway with input filtering, output scanning, and structured audit logging. |
| Apply NIST AI RMF functions | Use Govern, Map, Measure, and Manage to create continuous risk controls tied to named model owners and compliance cycles. |
| Automate your asset inventory | Unknown AI assets are unprotected assets. Use Azure Resource Graph, AWS Config, or equivalent tools to maintain a live inventory. |
Most teams I talk to treat the API gateway as the security perimeter for AI deployments. That instinct is understandable, but it is wrong in a way that creates real exposure.
The actual perimeter in a secure machine learning deployment spans four distinct layers: the artifact supply chain, the runtime environment, the inference API, and the data pipeline feeding the model. I have seen organizations with excellent API gateway configurations that were completely blind to tampered model weights sitting in an S3 bucket with overly permissive IAM policies. The gateway protected the front door while the artifact store was wide open.
Managed cloud services compound this. When you deploy on Azure Machine Learning or AWS SageMaker, the provider handles infrastructure security, but you remain fully responsible for model artifact integrity, prompt handling, output filtering, and access governance. The shared responsibility model does not shift artifact security to the cloud provider. Many teams discover this gap during a security audit rather than before one.
The other underestimated risk is the retrieval augmentation layer. RAG architectures introduce a new attack surface at the document retrieval step, where injected content in a knowledge base can manipulate model outputs without ever touching the inference API. Locking down your vector database and document ingestion pipeline deserves the same attention as your API gateway configuration.
My practical advice: map your AI deployment against all four layers before you write a single security policy. The gaps almost always appear at the artifact layer and the data pipeline, not at the API edge where most teams focus.
— Matthieu
Hymalaia is built for enterprises that cannot afford to treat AI security as an afterthought. The platform provides enterprise-grade AI agent capabilities with RBAC, GDPR-compliant data handling, and governance controls embedded directly into the deployment architecture. Every agent operates within defined access boundaries, and all data connections across Salesforce, SharePoint, Slack, and Google Workspace are governed by role-based policies and audit logging. Whether you deploy on cloud, on-premise, or hybrid infrastructure, Hymalaia gives your IT and data science teams the controls they need to run AI in production with confidence. Explore the Hymalaia platform to see how enterprise AI governance and secure deployment work together at scale.
Secure AI model deployment is the controlled process of moving AI models into production with protections across governance, access control, artifact integrity, and runtime monitoring. It covers the full lifecycle from model packaging to inference, not just the hosting environment.
The most common risks include tampered model artifacts, unsecured inference APIs, prompt injection attacks, and untracked AI assets that fall outside monitoring coverage. OWASP’s GenAI guidance identifies training data, prompts, and outputs as the primary attack surfaces in generative AI deployments.
NIST AI RMF provides four governance functions: Govern, Map, Measure, and Manage. Applied to deployment, these functions establish ownership policies, maintain asset inventories, quantify risks through testing, and define treatment strategies such as mitigation or human review for high-risk model actions.
Public cloud deployments on platforms like AWS or Azure offer managed infrastructure controls but introduce shared tenancy and data residency risks. Private deployments give full stack control and data locality at the cost of higher operational overhead for patching, key management, and monitoring.
Apply cryptographic signing with HSM-managed keys, maintain immutable version registries using tools like MLflow or DVC, and verify artifact hashes at every pipeline stage before deployment. Signed manifests and provenance metadata enable auditability and safe rollback when a compromised artifact is detected.
