TL;DR:
- AI indexing enhances enterprise search by integrating hybrid retrieval, real-time data freshness through CDC, and permission-aware enforcement for secure, accurate results. It requires ongoing governance, tiered freshness strategies, and pre-filter ACLs to ensure compliance and operational trust in AI-driven data retrieval systems. Evaluating solutions involves confirming support for hybrid architecture, incremental updates, permission controls, and scalable performance.
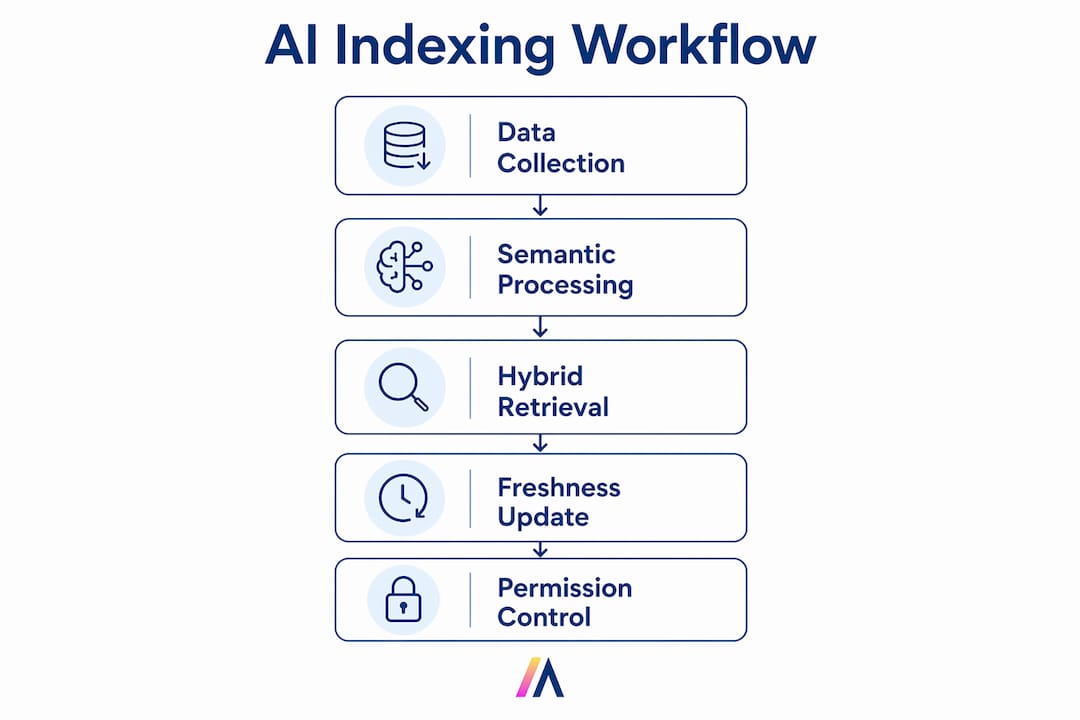
AI indexing in enterprise search is defined as the process of transforming raw organizational data into semantically enriched, permission-aware, and continuously updated retrieval structures that go far beyond traditional keyword matching. The core reason why enterprise search needs AI indexing comes down to four irreducible requirements: semantic understanding, hybrid retrieval precision, real-time freshness, and access-controlled results. Platforms like OpenSearch, Databricks, and Oracle have already embedded hybrid AI indexing into their core architectures, signaling that keyword-only search is no longer viable at enterprise scale. Organizations that still rely on pure lexical indexes are retrieving answers that are less accurate, potentially stale, and dangerously unaware of who should see what.
Hybrid AI indexing is the architecture that combines BM25 keyword (lexical) matching with dense vector (semantic) search into a single retrieval pipeline. This matters because neither method alone is sufficient for enterprise corpora, which contain everything from exact product codes and contract numbers to conceptual policy documents and unstructured meeting notes.

Lexical search excels at exact-term retrieval. If a user queries “SOC 2 Type II audit report Q3 2025,” BM25 will surface documents containing those exact tokens. Vector search, by contrast, retrieves documents based on semantic similarity, meaning a query about “vendor security compliance” can surface the same audit report even without matching keywords. The problem is that dense embeddings alone miss exact-term queries common in enterprise corpora, and combining BM25 lexical search with dense retrieval reduces retrieval failures by 67%.
OpenSearch supports hybrid search pipelines combining vector similarity with lexical search, and Databricks and Oracle provide similar hybrid keyword-similarity functionalities in their AI vector indexes. Oracle’s implementation goes further: its hybrid vector index exposes a single API allowing keyword, vector, or hybrid search modes, letting developers switch retrieval strategies without rebuilding the index.
A production-ready hybrid search architecture treats retrieval as a multi-stage funnel: BM25 retrieval first, then dense vector retrieval, followed by candidate list fusion, and finally optional cross-encoder reranking for best accuracy within latency budgets. This pipeline design is the current gold standard for enterprise search optimization.
| Approach | Strengths | Weaknesses |
|---|---|---|
| Pure keyword (BM25) | Exact-match precision, low latency, interpretable | Fails on synonyms, paraphrases, and conceptual queries |
| Pure vector (dense) | Semantic understanding, handles paraphrases | Misses exact terms, higher compute cost, opaque scoring |
| Hybrid (BM25 + vector) | Covers both exact and semantic needs, best recall | Higher architectural complexity, requires tuning fusion weights |
Pro Tip: When configuring hybrid search, start with a 0.7 vector / 0.3 BM25 fusion weight and adjust based on your corpus. Technical documentation corpora favor higher BM25 weight; policy and knowledge base content favors higher vector weight.
One often-overlooked optimization is contextual retrieval, where an LLM prepends 50 to 100 tokens of situating context at index time. This technique reduces retrieval failures by up to 49% without adding query-time latency, making it a high-value addition to any hybrid pipeline.
Stale indexes are not a minor inconvenience. They are an operational liability. 73% of organizations report accuracy degradation within 90 days due to knowledge staleness, and this exceeds the degradation caused by embedding quality issues. That means your retrieval infrastructure can be technically excellent and still deliver wrong answers because the underlying index has not kept pace with your data.
The traditional response to this problem is nightly full reindexing. It fails for two reasons. First, it creates a guaranteed staleness window of up to 24 hours. Second, re-embedding an entire enterprise corpus nightly is financially prohibitive at scale. The operationally viable alternative is change data capture (CDC) combined with chunk-level hashing.
Here is how the CDC approach works in practice:
An enterprise RAG case study shows 95% of updates visible in retrieval within one hour using CDC-driven chunk-level re-embedding, reducing re-embedding cost by 100x compared to full reindexing. That is the difference between a freshness SLA of one hour and one of 24 hours, at a fraction of the cost.
Pro Tip: Treat freshness as a tiered requirement, not a single SLA. Pricing pages and product specs may need sub-hour freshness. Internal HR policies may tolerate 24-hour cycles. Archived contracts may need weekly updates at most. Segment your index by content decay rate and apply CDC selectively to control costs.
Enterprises should treat their knowledge base as infrastructure requiring continuous maintenance, not a one-time build. This shift in mindset, from “index once” to “govern continuously,” is what separates organizations that trust their AI search results from those that quietly stop using them.
Access control in enterprise AI indexing is not a feature. It is a security boundary. Without it, a vector search query can surface confidential board minutes, HR records, or M&A documents to any user whose query happens to be semantically similar to those documents. This is the privilege escalation risk that makes permission-unaware AI indexing a compliance failure waiting to happen.
The technical distinction that matters here is pre-filter versus post-filter ACL enforcement:
Post-filter ACL breaks recall and leaks information; pre-filter ACL baked into retrieval preserves both recall and security. Amazon Kendra and vector databases like Weaviate support pre-filter ACL to maintain security and retrieval effectiveness.
Best practices for ACL-aware indexing architectures include:
For organizations operating under GDPR, HIPAA, or SOC 2 requirements, ACL enforcement at the vector layer is a direct compliance requirement. Ignoring it does not just create security risk. It creates auditable liability.
Selecting an AI indexing solution requires evaluating capabilities across four dimensions: retrieval architecture, freshness mechanisms, permission enforcement, and operational scale. Generic feature lists from vendors obscure the differences that matter in production.
When assessing retrieval architecture, confirm that the solution supports true hybrid search with configurable fusion weights, not just vector search with a keyword fallback. Ask whether the system supports cross-encoder reranking as a second-stage retrieval step. Reranking adds latency but can recover precision lost in the first-stage retrieval. For most enterprise use cases, a latency budget of 300 to 500 milliseconds accommodates a reranking step without degrading user experience.
For freshness, the key question is whether the platform supports CDC-driven incremental re-embedding or requires full reindexing on updates. Full reindexing at scale is not just slow. It is cost-prohibitive. Confirm that the solution supports chunk-level granularity for change detection, not just document-level updates.
Use this checklist when evaluating any AI indexing platform for enterprise deployment:
Performance benchmarking should include recall@10 and Mean Reciprocal Rank (MRR) across both exact-match and semantic query types. A solution that scores well on semantic queries but poorly on exact-match queries will frustrate users searching for specific document identifiers, product codes, or regulatory references. For a broader view of where AI indexing fits within enterprise AI strategy, the 2026 enterprise AI trends guide provides useful strategic context.
AI indexing transforms enterprise search by combining hybrid retrieval, real-time freshness via CDC, and pre-filter ACL enforcement into a single governed architecture that keyword search cannot replicate.
| Point | Details |
|---|---|
| Hybrid indexing is the baseline | Combining BM25 and vector search reduces retrieval failures by 67% versus either method alone. |
| CDC enables sub-hour freshness | Chunk-level incremental re-embedding cuts re-embedding cost by 100x and achieves 95% update visibility within one hour. |
| Pre-filter ACL is a compliance requirement | Post-filter access control leaks data via timing side channels; pre-filter enforcement at the ANN stage is the only secure approach. |
| Freshness requires tiered governance | Segment content by decay rate and apply freshness SLAs selectively to control cost without sacrificing accuracy. |
| Evaluation must cover four dimensions | Assess retrieval architecture, freshness mechanisms, permission enforcement, and scale before selecting any AI indexing solution. |
After working with enterprise teams implementing AI-powered search, the pattern I see most often is this: organizations invest heavily in embedding model selection and almost nothing in index governance. They spend weeks benchmarking OpenAI’s text-embedding-3-large against Cohere’s embed-v3 and then deploy on a nightly full-reindex schedule with no ACL enforcement at the retrieval layer. The result is a technically impressive demo that quietly degrades in production.
The uncomfortable truth is that embedding quality is the least important variable once you cross a quality threshold. What actually determines whether enterprise AI search succeeds in production is freshness discipline, permission architecture, and retrieval pipeline design. A well-governed hybrid index with a mid-tier embedding model outperforms a poorly governed index with a state-of-the-art model every time.
I also see teams treat AI indexing as a one-time infrastructure build rather than an ongoing operational practice. Index governance, including freshness monitoring, ACL synchronization, and retrieval quality audits, needs to be owned by a named team with defined SLAs. Without that ownership, indexes drift, answers degrade, and users stop trusting the system. That loss of trust is far harder to recover than the technical debt that caused it.
For teams serious about getting this right, enterprise AI governance best practices provide a practical framework for building the operational discipline that AI indexing requires long-term.
— Matthieu
Hymalaia’s enterprise AI platform is built for exactly the challenges this article describes. Its advanced RAG and AI indexing capabilities support hybrid retrieval across more than 50 connected data sources, including Salesforce, SharePoint, Slack, and Google Workspace. Freshness is handled through real-time data synchronization, not batch reindexing. Permission-aware retrieval is enforced at the retrieval layer with role-based access controls aligned to your existing identity infrastructure.
For enterprise teams that need accurate, secure, and current search results across complex data environments, Hymalaia delivers the governance, scale, and retrieval precision that production AI search demands. Explore Hymalaia’s platform to see how it fits your organization’s search and data retrieval requirements.
AI indexing in enterprise search is the process of converting organizational data into semantically enriched, permission-aware retrieval structures using techniques like vector embeddings, hybrid BM25 plus vector pipelines, and change data capture for continuous freshness.
Hybrid search combines BM25 lexical matching with dense vector retrieval, reducing retrieval failures by 67% compared to either method alone. It handles both exact-term queries and conceptual, paraphrase-based queries within a single pipeline.
Sub-hour freshness is achievable and cost-effective using CDC-driven chunk-level re-embedding, which reduces re-embedding cost by 100x versus nightly full reindexing. Content with high decay rates, such as pricing or product data, should target sub-hour SLAs.
Post-filter ACL enforcement leaks data through timing side channels and collapses retrieval recall. Pre-filter ACL applied at the approximate nearest neighbor query stage is the only architecture that preserves both security and retrieval quality.
Monitor recall@10 and MRR scores against a labeled query set on a weekly basis. Track the percentage of document chunks updated within your freshness SLA window. Unexplained drops in either metric typically indicate staleness or ACL misconfiguration rather than embedding model issues.
